Kasper König
This is follow-up post to how to build your own blockchain with crystal. I was following along this tutorial on how to build a basic blockchain in crystal to familiarize myself with the syntax, and while it was a very helpful blockpost - I wasn’t completely happy with where it ended. True, the concept of mining had been explained, somewhat. The block integrity was there. But then I went on with the guide, I deployed it to AWS ECS / Fargate, and the limitations started to annoy me even more. We are scaling with individual blockchains - we have a centralized blockchain - a node has a chain, and is the authority on blocks it creates. difficulty is at it’s discretion.
I decided to continue where the author left of, and demonstrate how we can turn such a blockchain into a distributed system with real consensus mechanisms in place. This might take a few posts.
As I’m doing this to strenghten my understanding of crystal, I might make some detours. We’ll see how it goes.
First things first
If you haven’t read the blogpost, I urge you to follow along yourself. After completion you’ll have a webserver with two endpoints:
GET /, which renders the blockchain as JSON for you to inspect.
POST /new_block where you can command the webserver to create a new block with
some input data - a string of your choosing, which will be commited to the
blockchain when the endpoint finishes mining the block.
After finishing the solution, I decided to refactor the end results to use a
Block class instead of a module that manipulates a NamedTuple. This change
allows us to better follow and reason about how our blocks behave. See for
yourself how the code changed
In particular, the Block.generate method now reads a lot easier:
def self.generate(last_block, data)
block = Block.new(
last_block.next_index,
Time.local.to_s,
data,
last_block.hash,
)
until block.hash_under_target?
puts "Mining! Not solution: #{block.render}"
block.increment_nonce!
end
puts "Mining complete! Solution: #{block.render}"
block
endWe could clean it up more, but I think it surfices for now.
You can try to follow the refactoring (I did some things slightly differently from the tutorial to begin with, but it’s not very different) - or you can clone my project as it was when I started this post.
git clone git@github.com:kholbekj/derpchain.git`
git checkout cc96c7583d6e2052f4f48f7e1837bc850b2b155b
A few caveats
I’m not going to be writing tests. I know, I know. While I’m generally a fan of TDD, I find that there’s still a big overhead for me in crystal, and I really don’t want to try to understand how to test crystal concurrency before having some hands on with how it works.
The second is, I’m designing this with bitcoin in mind. It just means that I’m trying to illustrate how transactions can be commited, double-spend prevented, and incentives kept in check. I believe understanding this is a great foundation, regardless of the kind of blockchain you’d like to better understand. Ethereum took the ideas a lot further in terms of possibilities, while bitcoin dealt with scaling the basics - there’s many interesting learnings from both, but here we’ll stick with a basic monetary system.
What actually is data?
In order to understand the relationship between the miner and the user trying to
use the system, we need to talk about the data field in our blockchain.
In bitcoin, data is generally a transaction. I might get into how to make those
secure later on, but for now we’ll go simple - there’s just two kinds of data
we’re interested in - the creation of coins, and the spending of coins.
Essentially we want to only write data of the following style to the blockchain:
"I am creating 10 coins for Bob"
"I, Bob, am sending Alice 5 coins"
Conveniently, only the miner gets to put the first message in the block (this is their reward for mining), so our endpoint only needs to support the second kind of message.
Since we’re going to be having more than one message per block (or we’d always
only create coins), we will need to change data to be an array of strings,
instead of just a string.
First we switch the signature of the Block initializer:
def initialize(@index : Int32, @timestamp : String, @data : Array of String, @prev_hash : String)
@nonce = 0
@hash = calculate_hash
endthen, we fix the places where we call Block.new
in block.cr:
def self.generate(last_block, data)
block = Block.new(
last_block.next_index,
Time.local.to_s,
["I am creating 10 coins for Bob", data],
last_block.hash,
)and in crystal-blockchain.cr:
blockchain << Block.new(0, Time.local.to_s, ["I am creating 10 coins for Bob"], "")When we now query our GET / endpoint, we see that data is now an array
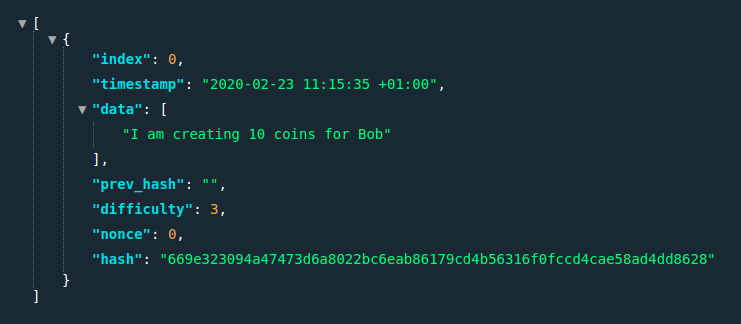
Ledger
It might be worth talking about ledger and state for a minute. It might not be obvious that what we now have is actually all that is needed for bitcoin, in terms of how to own and spend money. The blockchain has inside it a very long list of statements like what we’ve added - transactions from the miner to Bob (creating coins out of thin air), and transactions from Bob to someone else. Whenever alice wants to send coins to Eve, we first need to check that somewhere in the list of transactions is one that hands over enough coins for Alice to do so, and also that she didn’t already send those coins somewhere.
When we later want to build these rules into our system we can, but for now we have a system which works as long as no-one cheats - and we can expose cheaters by just reading through the transactions.
Mining all the time!
Our current solution has an obvious problem: if a Miner can get 10 coins every time they mine a block, they don’t want to wait for someone to try to add data - they want to be constantly mining, and including data when there is some.
This requires some more drastic change to how our system works. First off, our
POST /new_block endpoint now has an awkward name. Second, we need our program
to do something constantly, but somehow buffer the data that comes in from
users.
First, let’s get rid of our new_block endpoint and get the mining running on
it’s own. We delete the post call from crystal-blockchain.cr, making it nice and
slim:
require "kemal"
require "./block"
module Crystal::Blockchain
VERSION = "0.1.0"
blockchain = [] of Block
blockchain << Block.new(0, Time.local.to_s, ["I am creating 10 coins for Bob"], "")
get "/" do
blockchain.to_json
end
Kemal.run
endSince we’ll be mining constantly, let’s make it a bit slower. We could do this
by changing the difficulty, but to simulate it without smashing our CPU, we can
introduce a little sleep step to Block#calculate_hash:
def calculate_hash : String
sleep(0.01)
plain_text = "This will make a block take somewhere around 30 seconds to a minute on average. I might regret this.
Next, we need to get the application to mine on it’s own, but we still want to
respond to web requests so we can show off the state of our blockchain. We can’t just
introduce a loop before Kemal.run, as the server would never start listening.
We need a Fiber - crystal’s concurrency primitive. A fiber is like a threat -
but it’s managed by crystal’s own scheduling system. Our use-case is rather
easy, we just need a loop that get’s CPU time whenever our webserver isn’t doing
anything. Luckily, crystal prioritizes the “main” fiber (crystal-blockchain.cr)
highest. So all we have to do is spawn a thread to mine before Kemal.run, and
things will work as we want:
get "/" do
blockchain.to_json
end
spawn do
loop do
block = Block.generate(blockchain.last, "I, Bob, am sending 5 coins to Alice")
blockchain << block if block.valid?(blockchain.last)
end
end
Kemal.runCurrently our Block.generate method does not work without data, but Alice is
paying for Bob’s electricity, so this way they can split the rewards!
Getting other transactions
Of course now the blockchain will only consist of blocks generating coins for Bob and Alice, and they will have a hard time convincing their friends to participate. We need to re-introduce an API for users to submit tranascations. However, differently from before, this should just be added to whatever block we are currently mining, not create a whole seperate block.
We might also take this time to clean up the interface a bit. Since we only expect messages of the type: “I, SENDER, am sending AMOUNT coins to RECIPIENT”, we might as well make those three variables actual fields of our API.
We can start with a basic endpoint:
get "/" do
blockchain.to_json
end
post "/add_transaction" do |env|
sender = env.params.json["sender"].as(String)
amount = env.params.json["amount"].as(Int64)
recipient = env.params.json["recipient"].as(String)
data = "I, #{sender}, am sending #{amount} coins to #{recipient}"
data
endWe can query it from Postman with:
POST /add_tranasaction
{
"sender":"Alice",
"amount":3,
"recipient":"Eve"
}giving us the response
"I, Alice, am sending 3 coins to Eve"
We’ll need to fix that response, but first we face a problem: how do we let our fiber running the loop know to include this new data? Well, first we neeed to be able to add more data to a block - let’s open up our block.cr class:
def add_transaction!(transaction : String)
@data << transaction
endThe next thing we need is a way to get that data into our fiber. The prefered way to do so in crystal is with a channel. Channels are two-way message systems that fibers can use to let each other know to do things.
First, let’s set up a channel that can carry strings around next to our blockchain variable:
blockchain = [] of Block
blockchain << Block.new(0, Time.local.to_s, ["I am creating 10 coins for Bob"], "")
channel = Channel(String).newThen in our endpoint, we send our newly constructed data to it:
post "/add_transaction" do |env|
sender = env.params.json["sender"].as(String)
amount = env.params.json["amount"].as(Int64)
recipient = env.params.json["recipient"].as(String)
data = "I, #{sender}, am sending #{amount} coins to #{recipient}"
channel.send(data)
data
endNow, when the endpoint reaches channel.send(data), it will stop moving on, and
wait for channel to receive that message somewhere.
To make that happen we’ll need to have our mining loop react - but doing it
between blocks is too slow - the endpoint would take as long to return as a
block takes to mine. Rather, we can pass the channel as an argument to the
Block.generate method, and add transactions directly into the mining loop:
spawn do
loop do
block = Block.generate(blockchain.last, "I, Bob, am sending 5 coins to Alice", channel)
blockchain << block if block.valid?(blockchain.last)
end
endand in block.cr we add the new argument, and a step in the until loop that
adds a new transaction to the block if one is available:
def self.generate(last_block, data, transaction_channel)
block = Block.new(
last_block.next_index,
Time.local.to_s,
["I am creating 10 coins for Bob", data],
last_block.hash,
)
until block.hash_under_target?
puts "Mining! Not solution: #{block.render}"
select
when transaction = transaction_channel.receive
block.add_transaction!(transaction)
else
end
block.increment_nonce!
end
puts "Mining complete! Solution: #{block.render}"
block
endThe select/when/else structure is (at time of writing) still undocumented, but
it essentially allows us to check if we can receive a message, and if not
execute the else clause - which we are leaving empty.
We then let it increment the nonce as normal, and continue mining. We could reset it here, but it would make the logs a bit harder to follow.
That’s it! Spin up the application, and we can now see that it mines away happily, but includes new transaction when the endpoint is called - happilly more than once per block.
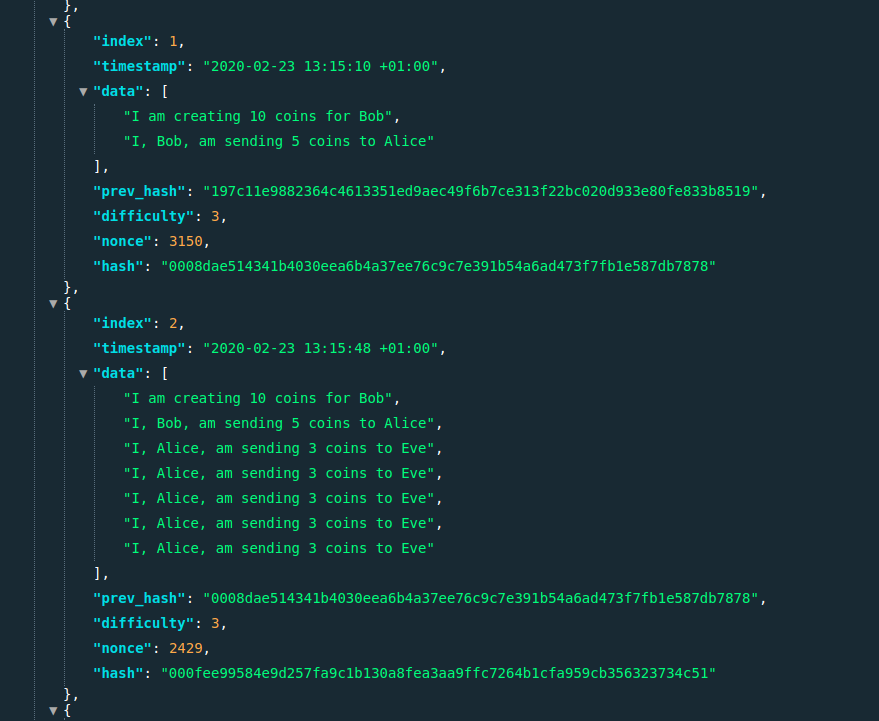
Recap of what we’ve accomplished already
What we have now is a system that - while requiring some manual work to really use - actually leverages the blockchain to some extend.
We can still sleep easy if we trust the operator of the server, as it’s centralized. But there’s an additional security mechanism - the longer the list grows, the harder it would be for an attacker to replace it, even if they would gain access to the state of our server. They would have to compute their own blockchain to replace it with - which we can verify if they really did, just by looking at the hashes, and verifying that the chain is correct.
This is still not very secure on a single server, as matching a single servers mining power is not that hard. We need more miners.
To be continued…